Benchmark Results
This page will be udpated soon with even more data 📈
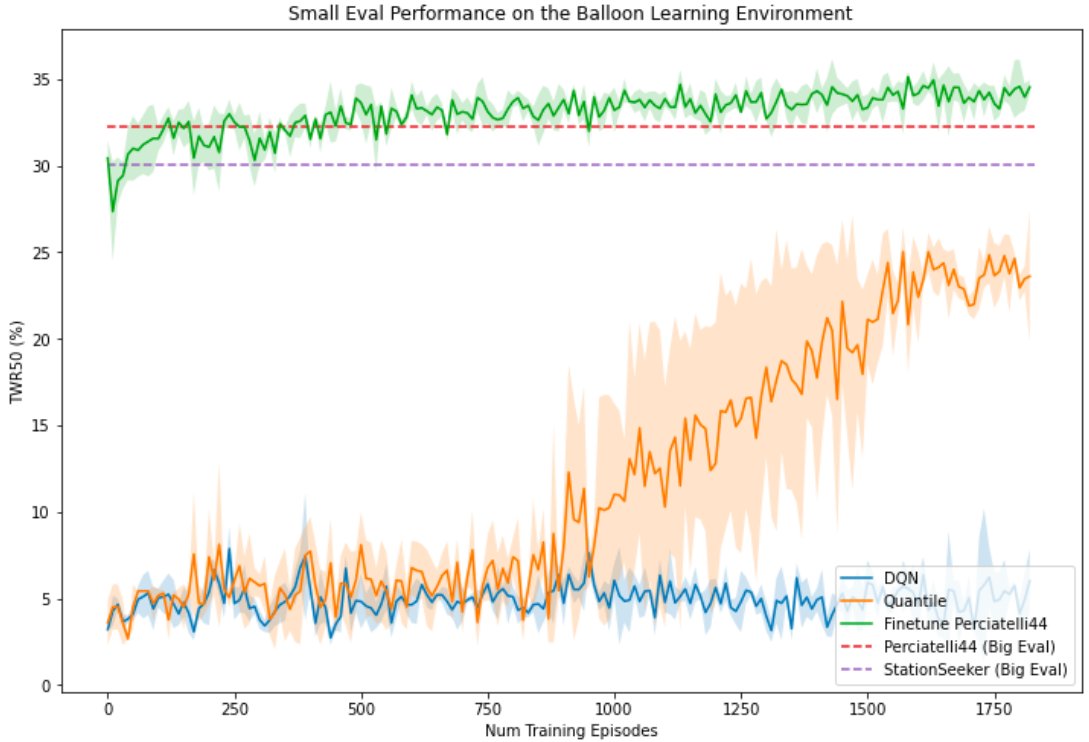
The following graph shows evaluation results on the “small eval” evaluation suite throughout training for the DQN, quantile, and finetuned Perciatelli44 agents. The horizontal lines are evaluation results for “big eval” for Perciatelli44 and station seeker.